
This is a fascinating time in the study and application of large language models. New advancements are announced every day!
In this guide, I share my analysis of the current architectural best practices for data-informed language model applications. This particular subdiscipline is experiencing phenomenal research interest even by the standards of large language models - in this guide, I cite 8 research papers and 4 software projects, with a median initial publication date of November 22nd, 2022.
Overview
In nearly all practical applications of large language models (LLM’s), there are instances in which you want the language model to generate an answer based on specific data, rather than supplying a generic answer based on the model’s training set. For example, a company chatbot should be able to reference specific articles on the corporate website, and an analysis tool for lawyers should be able to reference previous filings for the same case. The way in which this external data is introduced is a key design question.
At a high level, there are two primary methods for referencing specific data:
- Insert data as context in the model prompt, and direct the response to utilize that information
- Fine-tune a model, by providing hundreds or thousands of prompt <> completion pairs
Shortcomings of Knowledge Retrieval for Existing LLM’s
Both of these methods have significant shortcomings in isolation.
For the context-based approach:
- Models have a limited context size, with the latest `davinci-003` model only able to process up to 4,000 tokens in a single request. Many documents will not fit into this context.
- Processing more tokens equates to longer processing times. In customer-facing scenarios, this impairs the user experience.
- Processing more tokens equates to higher API costs, and may not lead to more accurate responses if the information in the context is not targeted.
For the fine-tuning approach:
- Generating prompt <> completion pairs is time-consuming and potentially expensive.
- Many repositories from which you want to reference information are quite large. For example, if your application is a study aid for medical students taking the US MLE, a comprehensive model would have to provide training examples across numerous disciplines.
- Some external data sources change quickly. For example, it is not optimal to retrain a customer support model based on a queue of open cases that turns over daily or weekly.
- Best practices around fine-tuning are still being developed. LLM's themselves can be used to assist with the generation of training data, but this may take some sophistication to be effective.
The Solution, Simplified
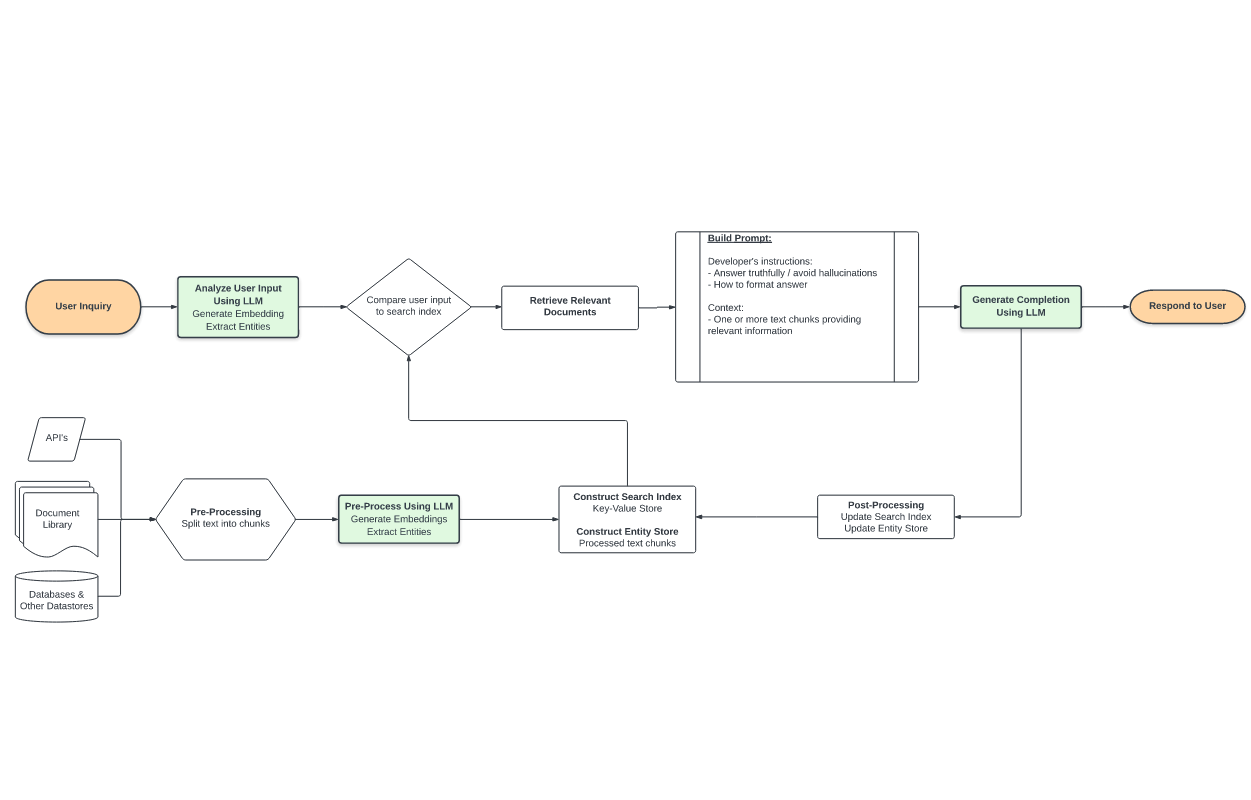
The design above goes by various names, most commonly "retrieval-augmented generation" or "RETRO". Links & related concepts:
- RAG: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- RETRO: Improving language models by retrieving from trillions of tokens
- REALM: Retrieval-Augmented Language Model Pre-Training
Retrieval-augmented generation a) retrieves relevant data from outside of the language model (non-parametric) and b) augments the data with context in the prompt to the LLM. The architecture cleanly routes around most of the limitations of fine-tuning and context-only approaches.
Retrieval
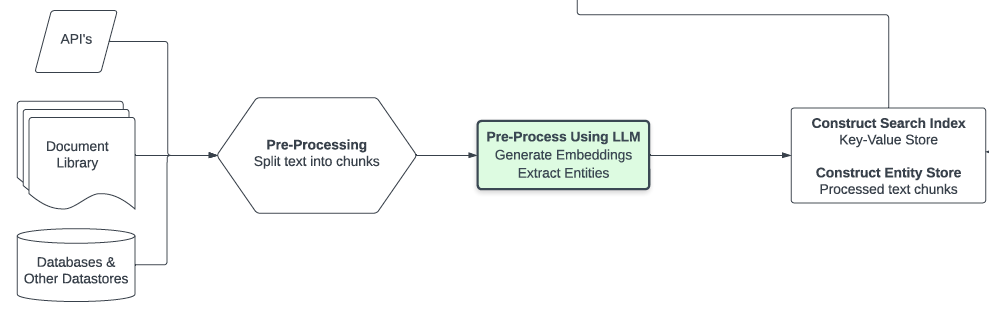
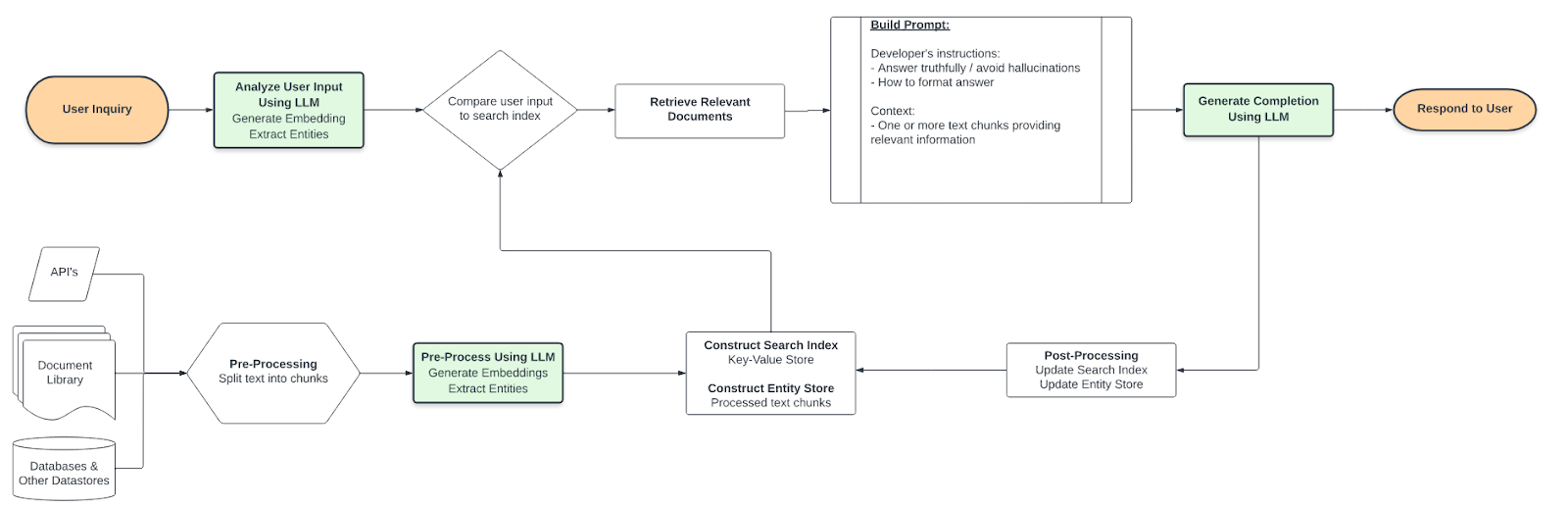
The retrieval of relevant information is worth further explanation. As you can see, data may come from multiple sources depending on the use case. In order for the data to be useful, it must be sized small enough for multiple pieces to fit into context and there must be some way to identify relevance. So a typical prerequisite is to split text into sections (for example, via utilities in the LangChain package), then calculate embeddings on those chunks.
Language model embeddings are numerical representations of concepts in text and seem to have endless uses. Here's how they work: an embeddings model converts text into a large, scored vector, which can be efficiently compared to other scored vectors to assist with recommendation, classification, and search (+more) tasks. We store the results of this computation into what I’ll generically refer to as the search index & entity store - more advanced discussions on that below.

Back to the flow – when a user submits a question, an LLM processes the message in multiple ways, but the key step is calculating another embedding - this time, of the user’s text. Now, we can semantically search the search index & entity store by comparing the new embeddings vector to the full set of precomputed vectors. This semantic search is based on the “learned” concepts of the language model and is not limited to just a search for keywords. From the results of this search, we can quantitatively identify one or more relevant text chunks that could help inform the user’s question.
Augmentation
Building the prompt using the relevant text chunks is straightforward. The prompt begins with some basic prompt engineering, instructing the model to avoid “hallucinating” i.e. making up an answer that is false, but sounds plausible. If applicable, we direct the model to answer questions in a certain format e.g. “High”,”Medium”, or “Low” for an ordinal ranking. Finally, we provide the relevant information from which the language model can answer using specific data. In its simplest form, we simply append (“Document 1: ”+ text chunk 1 + “\nDocument 2: ” + text chunk 2 + …) until the context is filled.
Finally, the combined prompt is sent to the large language model. An answer is parsed from the completion and passed along to the user.
That’s it! While this is a simple version of the design, it’s inexpensive, accurate, and perfect for many lightweight use cases. I’ve used this setup in an industry prototype to great success. A plug-and-play version of this approach can be found in the openai-cookbook repository and is a convenient starting point.
Advanced Design
I want to take a moment to discuss several research developments that may enter into the retrieval-augmented generation architecture. My belief is that applied LLM products will implement most of these features within 6 to 9 months.
Generate-then-Read Pipelines
This category of approaches involves processing the user input with an LLM before retrieving relevant data.
Basically, a user’s question lacks some of the relevance patterns that an informative answer will display. For example, "What is the syntax for list comprehension in Python?" differs quite a bit from an example in a code repository, such as the snippet "newlist = [x for x in tables if "customer" in x]". A proposed approach uses “Hypothetical Document Embeddings” to generate a hypothetical contextual document which may contain false details but mimics a real answer. Embedding this document and searching for relevant (real) examples in the datastore retrieves more relevant results; the relevant results are used to generate the actual answer seen by the user.
A similar approach titled generate-then-read (GenRead) builds on the practice by implementing a clustering algorithm on multiple contextual document generations. Effectively, it generates multiple sample contexts and ensures they differ in meaningful ways. This approach biases the language model towards returning more diverse hypothetical context document suggestions, which (after embedding) returns more varied results from the datastore and results in a higher chance of the completion including an accurate answer.
Improved Data Structures for LLM Indexing & Response Synthesis
The GPT Index project is excellent and worth a read. It utilizes a collection of data structures both created by and optimized for langauge models. GPT Index supports multiple types of indices described in more detail below. The basic response synthesis is “select top k relevant documents and append them to the context”, but there are multiple strategies for doing so.
- List Index - Each node represents a text chunk, otherwise unaltered. In the default setup, all nodes are combined into the context (response synthesis step).
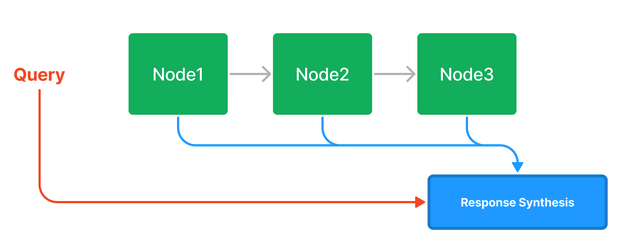
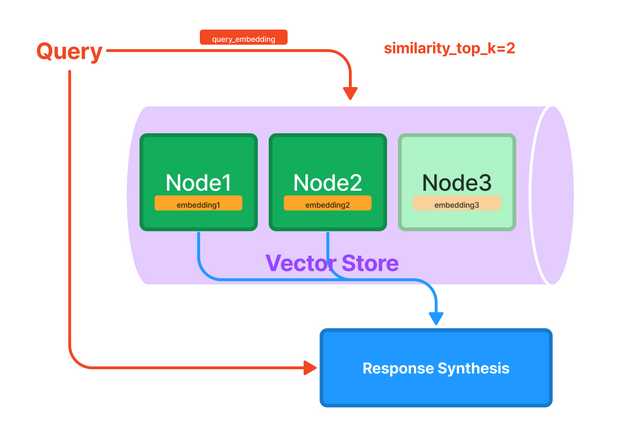
- Vector Store Index - This is equivalent to the simple design that I explained in the previous section. Each text chunk is stored alongside an embedding; comparing a query embedding to the document embeddings returns the k most similar documents to feed into the context.
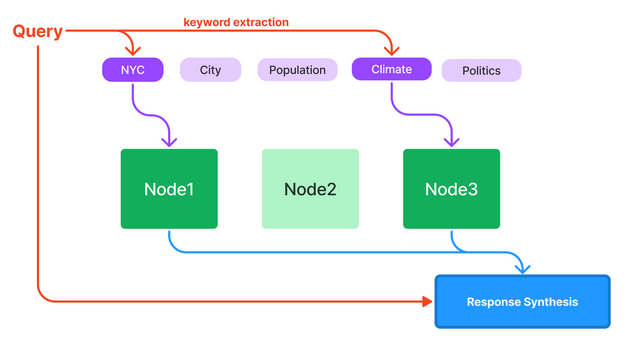
- Keyword Index - This supports a quick and efficient lexical search for particular strings.
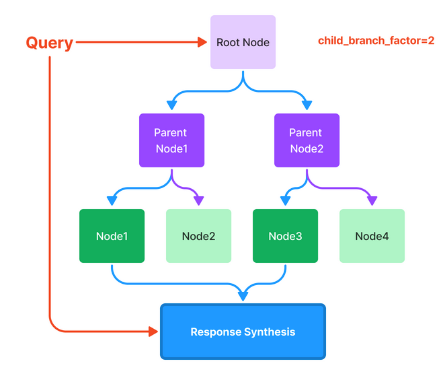
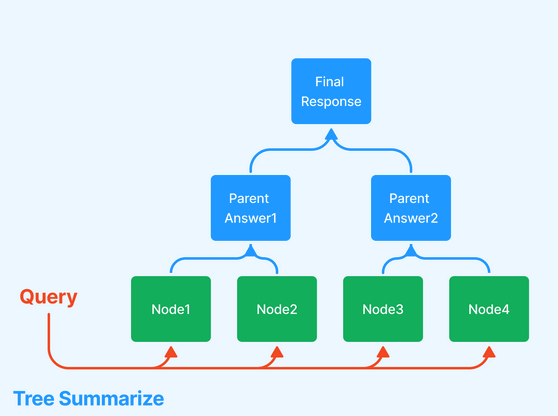
- Tree Index - This is extremely useful when your data is organized into hierarchies. Consider a clinical documentation application: you may want the text to include both high-level instructions ("here are general ways to improve your heart health") and low-level text (reference side effects and instructions for a particular blood pressure drug regimen). There are a few different ways of traversing the tree to generate a response, two of which are shown below.
- GPT Index offers composability of indices, meaning you can build indices on top of other indices. For example, in a code assistant scenario, you could build one tree index over internal GitHub repositories and another tree index over Wikipedia. Then, you layer on a keyword index over the tree indices.
Expanded Context Size
Some of the approaches outlined in this post sound "hacky" because they involve workarounds to the relatively small context size in current models. There are significant research efforts aimed at expanding this limitation.
- GPT-4 is anticipated within the next 1-3 months. It is rumored to have a larger context size.
- This paper from the folks at Google AI features a number of explorations of engineering tradeoffs. One of the configurations allowed for a context length of up to 43,000 tokens.
- A new state space model architecture scales ~linearly with context size instead of quadratically like seen in transformer models. While the performance of this model lags in other areas, it demonstrates that significant research efforts are targeted at improving model considerations such as context size.
In my opinion, advancements in context size will scale alongside demands for more data retrieval; in other words, it's safe to assume that text splitting and refinement will continue to be required, even as some configurations evolve.
Persisting State (e.g. Conversation History)
When LLM’s are presented to the user in a conversational form, a major challenge is maintaining that conversation history in context.
An overview of the relevant strategies is beyond the scope of this post; for an example of a recent code demonstration involving progressive summarization and knowledge retrieval, see this LangChain example.
Resources & Further Reading
- GPT Index
- Haystack library for semantic search and other NLP applications
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- LangChain
- How to implement Q&A against your documentation with GPT3, embeddings and Datasette
- FAISS for vector similarity calculations
- Generate rather than Retrieve: Large Language Models are Strong Context Generators
- Implementation Code