
This is a repost of my feature on the Silectis blog.
With our Magpie platform, you can build a trusted data lake in the cloud as the shared foundation for analytics in your organization. Magpie brings together the tools data engineers and data scientists need to integrate data, explore it, and develop complex analytics.
For more information, reach out to me on my Contact Page or connect with me on LinkedIn.
Let’s face it, operating in a data-driven environment is hard. Teams, even small ones, can generate a painfully large number of batch processes that need to run on schedules. Drag-and-drop ETL tools become a maze of dependencies as business logic expands. Cron jobs lack transparency, failing silently and sucking away developer time.
It’s in response to these challenges that Apache Airflow was developed, and it has quickly attracted the attention of the data engineering community (for good reason!). The open-source platform helps users manage complex workflows, by defining workflows as code and supplying a suite of tools for scheduling, monitoring, and visualizing these processing pipelines. Its code-first design philosophy helps automate scripts that perform tasks but does so in a way that is flexible and resilient.
Airflow Basics
Workflows are defined as directed acyclic graph (DAG) objects that tie together tasks and specify schedules and dependencies. An important aspect to understand is that the DAG object only specifies how you want to carry out a workflow and the relationships between component tasks. The DAG doesn’t do any processing itself and simply lays out the blueprint for a sequence of tasks.
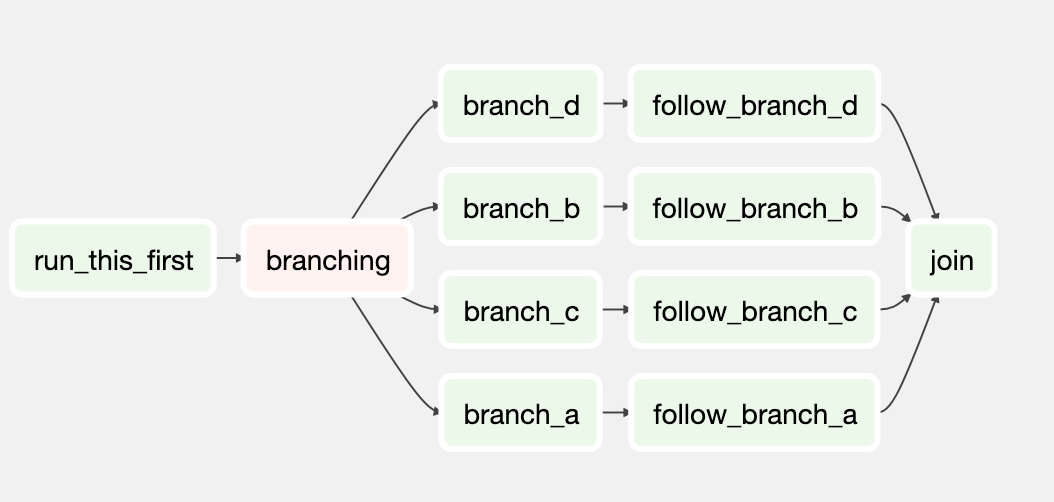
Operators can be thought of as customizable “connectors” - these provide abstractions for external systems and specify what actually gets done. Airflow provides many built-in operators such as BashOperator for executing bash scripts and PythonOperator for executing Python callables. These templates are incredibly useful for ensuring that systems interact predictably.
A task is a representation of an operator with a particular set of input arguments.
To sketch out an example, you could orchestrate an hourly load of a data warehouse within a single DAG. While there’s only one BigQueryOperator, each table-loading step would instantiate a task by passing a custom SQL script to the BigQueryOperator. The DAG might conclude with tasks communicating the job status to Slack and external monitoring tools (not all operators process data).
For a typical team, this architecture helps engineers spend less time wrangling the nuances of external API’s and more time integrating disparate resources like Salesforce, Kubernetes, or Sagemaker.
Airflow’s user interface allows users to monitor pipeline status and better understand the dependencies in your organization’s data. The design surfaces the progress of job executions so that data scientists, analysts, and data engineers can collaborate in productive ways that aren’t feasible with traditional ETL tools or standalone scripts.
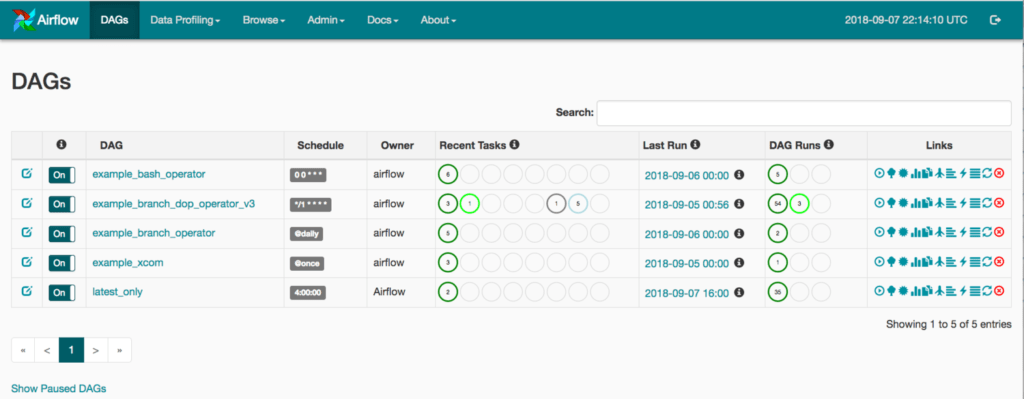
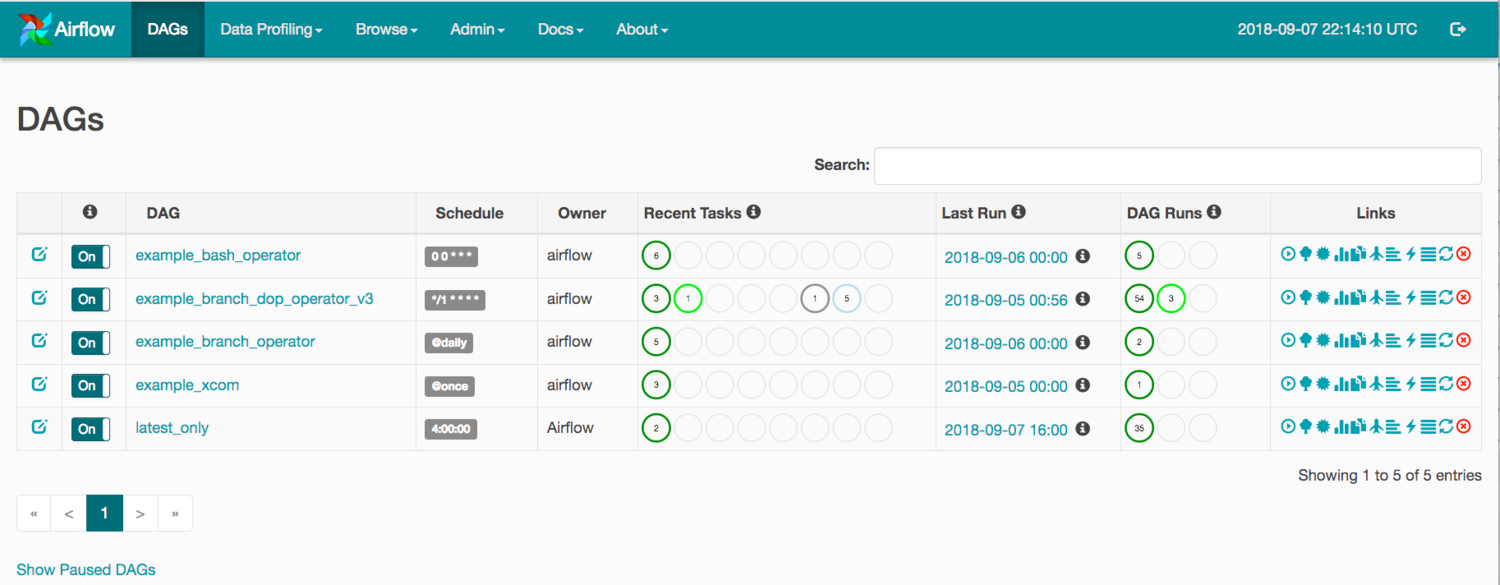
Airflow’s “DAGs View”:
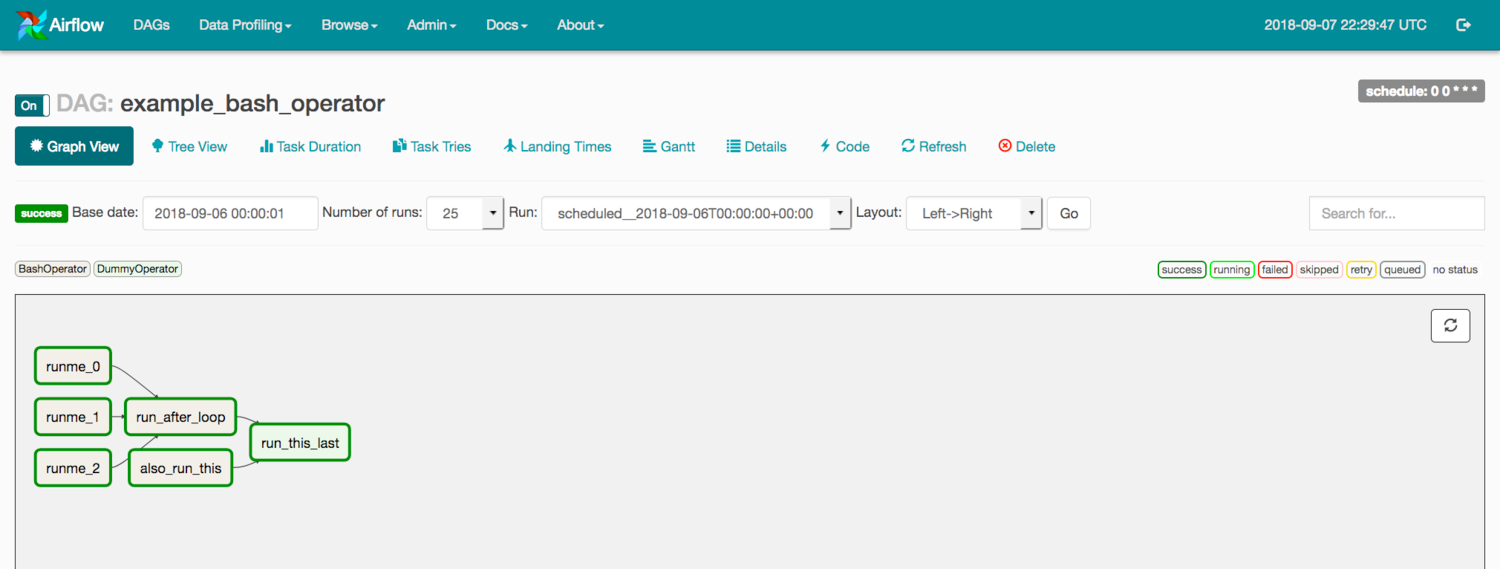
Airflow’s “Graph View”:
Combine these capabilities with a strong developer community and adoption at established companies like Lyft, Slack, and Twitter, and you can see why it’s an easy choice for companies seeking to build maintainable, reliable, and scalable data pipelines.
Why does integrating Airflow with Silectis Magpie make sense?
Businesses are facing an array of challenges as they seek to become more data-driven. The diversity of data is increasing: more sources need to be integrated, including sources external to an organization. Data volumes are exploding as all aspects of commerce become more digitized. And businesses expect data to be up to date and readily available to answer the latest business questions.
At Silectis, we believe that these demands require a data lake architecture as a foundation for modern analytics. Our managed data lake platform, Magpie, helps companies organize and derive value from their data, faster. Airflow can augment Magpie’s capabilities in several ways.
1. Data Ingestion and Organization
Out of the box, Silectis Magpie provides capabilities for integrating with distributed file systems like Amazon S3 or with databases accessible via JDBC connection. It provides language flexibility to connect with API’s via Python or Scala. The platform’s core computing engine leverages the Apache Spark framework to meet performance needs at any scale.
Airflow layers on additional resiliency and flexibility to your pipelines so teams spend less time maintaining and more time building new features. Two types of Airflow operators can assist with organizing and curating a data lake within Magpie.
The first is called a Sensor, which is a blocking tasks that waits for a specified condition to be met.
- Example: Airflow can monitor the file system of an external partner for the presence of a new data export and automatically execute a job in Magpie to ingest data once it’s available. Faster data means faster decisions.
Another category of Airflow operator is called a Transfer Operator. As the name implies, these connect two (or more) services together and enable data transfer between them (e.g. GoogleCloudStorageToS3Operator). The Airflow project’s rich developer contributions mean that data engineers rarely have start to from scratch.
- Example: Magpie can be deployed on multiple cloud providers (AWS, GCP, and Azure). However, organizations typically select one cloud provider to host their primary analytics workload. Integrating data across platforms is absolutely critical to provide a holistic view of the business. Airflow helps you move data into Magpie, even when hosted on another cloud provider.
2. Orchestrating External Systems
A strength of the data lake architecture is that it can power multiple downstream uses cases including business intelligence reporting and data science analyses. Unfortunately, the teams tasked with these activities often operate on separately managed infrastructure. Airflow can help bridge any gaps.
- Example: Upon successful loading of recent clickstream data in Silectis Magpie, Airflow uses the Kubernetes operator to spin up an ephemeral server cluster that the data science team uses for hyperparameter tuning of customer personalization models. Impact: reduce the interval for retraining, conduct more experiments, and achieve more goals of the machine learning program.
3. Advanced Dependency Management and Scheduling
Magpie captures rich metadata as it is operated, helping you better understand the shape and structure of your data lake. Surfacing this information to Airflow unlocks powerful features with minimal customization:
- Automatically refresh a table if Magpie indicates it has not been updated in X days
- Automatically execute backfill jobs for any period during which an Airflow schedule is defined as active but data is not present in Magpie
- Conduct Source & Target data validation (e.g. row counts, date ranges, presence of null values)
- Execute a pipeline if the destination table shows X% divergence from the source on a profiled metric
- Generate enriched audit reports using Magpie’s logging functionalities
- Allow for optional tasks - if a source file is unavailable, allow a job to proceed if it has been loaded successful in the last X days
Integrating Airflow & Magpie
There are many helpful resources for getting up and running with an initial deployment of Airflow. My recommended starting points are the Apache Airflow docs and the “Awesome Apache Airflow” repository on Github.
Alright, so now you have Airflow installed! For this introduction, let’s assume our goal is to utilize Airflow for scheduling and dependency management without venturing into the advanced use cases above.
At a general level, we will utilize Magpie’s command line interface (CLI) to connect the tools. There are a two primary ways we will interact with Magpie.
The first is by piping basic commands via the CLI to execute jobs already defined within Magpie (e.g. using exec job … syntax). The second is by passing files written in Magpie’s domain-specific language through the CLI, allowing for more flexibility to create, execute, and automate data loading tasks.
Example Magpie Script:
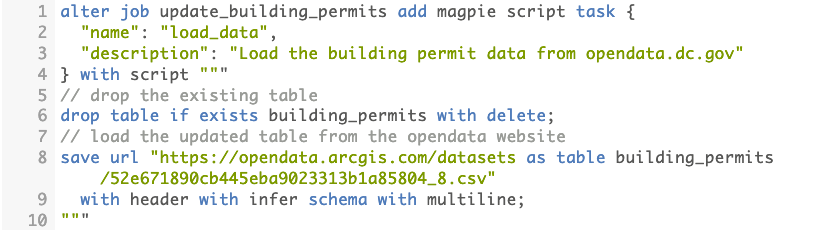
Either way, we utilize Airflow’s BashOperator. In Airflow terminology, each combination of a Magpie job or script and the bash operator is a task. We’ll aim to build out DAGs that sequence the tasks in a logical order.
Alright, let’s get down to business and install Magpie!
- Download the Magpie CLI. It is accessible in the drop-down menu in the top right of every Magpie notebook interface webpage.
- Unpack the ZIP file into a new directory within the
Airflowproject installed on your machine. - Set the environment variables
MAGPIE_USER,MAGPIE_PASSWORD, andMAGPIE_HOSTwith the appropriate credentials for your Magpie cluster. If you define them in the CLI’sconf/magpie-env.shfile, Magpie will read them automatically. - Depending on the installation location of the Airflow instance relative to your Magpie cluster, you may need to separately configure a VPN and/or modify firewall settings of your cloud provider.
- Restart the Airflow webserver, scheduler, and worker so that configuration changes take effect.
- In the Airflow UI, navigate to Admin > Variables and create a new variable,
magpie_pipe_location. Set its value as the installation location (full path) of the Magpie CLI. This will come in handy later when we construct templated commands.
That’s it! Now you’re ready to create your first DAG.
Usage
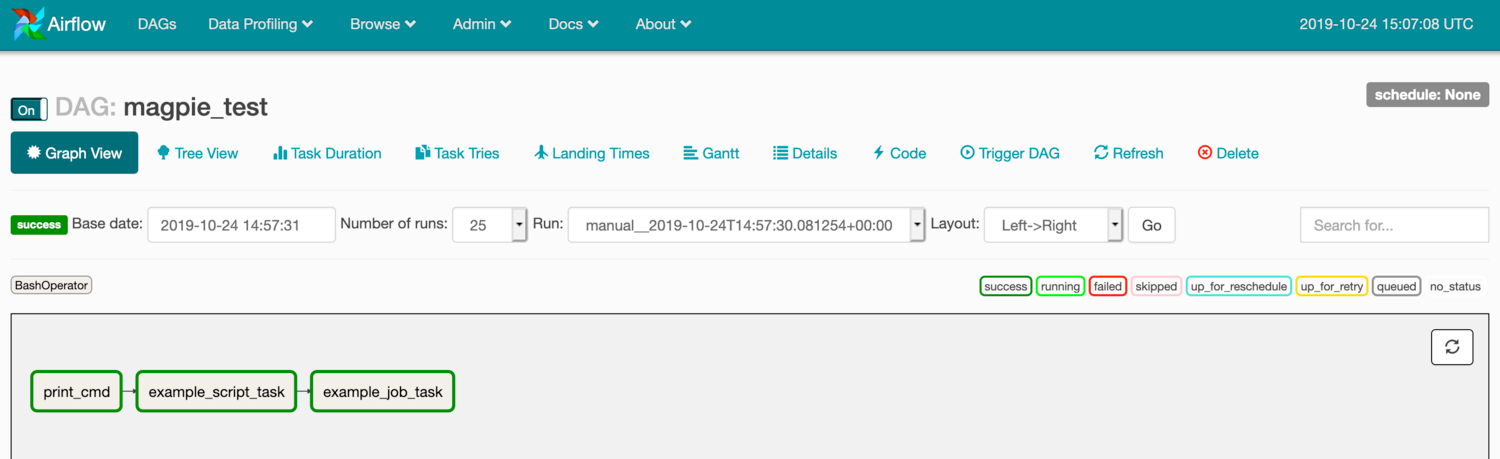
Here is a DAG which executes three Magpie tasks in sequence. The user interface shows a simple workflow, with color coding to indicate success/failure of the individual tasks as well as arrows to graph dependencies.
Clicking on the “Code” tab brings up the following UI. The DAG is set up in a typical manner except that we define three templated commands.
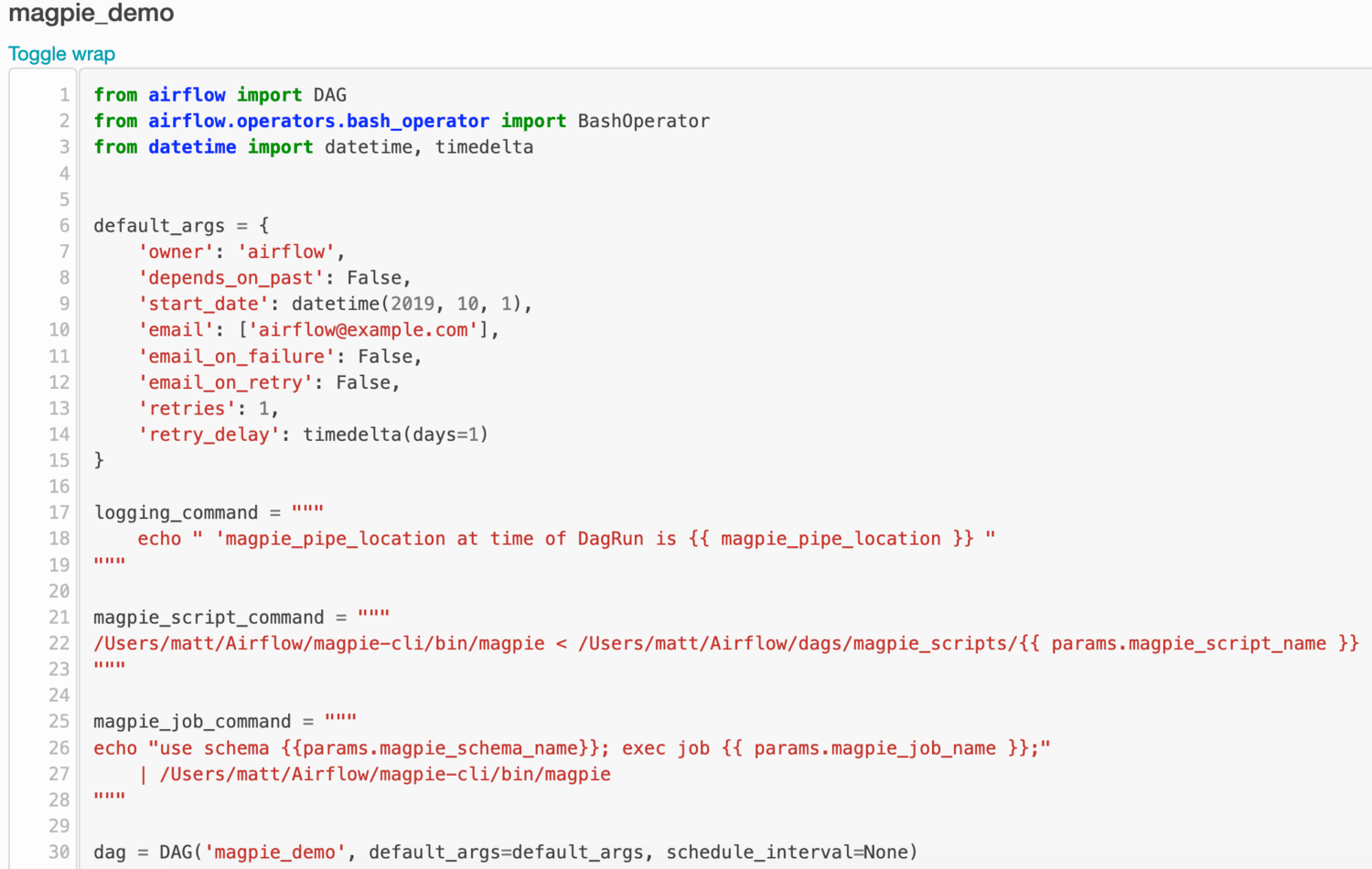
The first task logs the value of a variable for easier troubleshooting and debugging. It passes the logging_command template to Airflow and outputs the current value of the variable magpie_pipe_location.

The second task communicates a Magpie script to be processed by Magpie. This is quite powerful, as it logically isolates different parts of your system. The Magpie scripts can be modified remotely by analysts without a need to deploy new versions of DAGs to Airflow. The only parameter to pass along in the DAG definition is the Magpie script filename.

The final task executes arbitrary code in Magpie. In this case, I’ve constructed the template to use a commonplace “exec job …;” command from the Magpie domain-specific language. We pass the job name and schema name as parameters. The order of execution of tasks (i.e. dependencies) in Airflow is defined by the last line in the file, not by the relative ordering of operator definitions.

The DAG we’ve just defined can be executed via the Airflow web user interface, via Airflow’s own CLI, or according to a schedule defined in Airflow. It first logs the value of a variable, then executes a Magpie script and a Magpie job.
Wrapping Up
In just a few simple steps, we combined the extensive workflow management capabilities of Apache Airflow with the data lake management strengths of Silectis Magpie. While the example above is simple, the same techniques could be used to deploy a production-ready system.
If your organization is interested in setting up a data lake and wants to get up and running as quickly as possible, click here to see how Magpie can help.