

Intended audience: Basic understanding of AI/ML, basic familiarity with AI-generated art.
Tomorrow, the world will shift in an important way with the public release of the model weights for Stability AI's Stable Diffusion text-to-image engine. This will allow anyone to synthesize high-quality, detailed, creative images in a few seconds, on cheap consumer hardware. On its merits, this is one of the most important moments in the history of art, providing unconditional access to a start-of-the-art image model for free. Anyone will be able to use the model in their own applications and freely release customizations and improvements.
But what Stability AI is doing has impacts far beyond the AI Art world. This is going to be revolutionary and represents the mainstreaming of a powerful, portable, and extensible AI.
For context, most of today's AI-powered applications are narrowly-focused routines like fraud detection and content recommendation. They're undoubtedly powerful and help companies save or more effectively spend billions of dollars every year, but are hidden behind proprietary systems and are expensive to train and operate. But three key conceptual innovations are convincingly demonstrated in one package with the success of Stable Diffusion:
- Mainstreaming of Synthesis Engines
- Multi-domain Applications
- Alternate AI Deployment Patterns
Mainstreaming of Synthesis Engines
A.K.A. What's the big deal with a bunch of "An astronaut at the beach in the style of Van Gogh" images?
It's a truism that disruptive technologies are treated as a toy long before reaching prominence. In many ways, the recent discourse around AI-generated art is no different, but I've found that even those in the industry are focusing on small incremental improvements (e.g. "which model draws faces better?") and missing the big picture.
Synthesized images, video, text, and audio will become the defining mode of conveying the utopias we dream of and the dystopias we fear. If you can describe a vision for the future, you will be able to generate convincing & vivid multimodal portrayals.
"Voyage through Time"
— Xander Steenbrugge (@xsteenbrugge) August 13, 2022
is my first artpiece using #stablediffusion and I am blown away with the possibilities...
We're crossing a threshold where generative AI is no longer just about novel aesthetics, but evolving into an amazing tool to build powerful, human-centered narratives pic.twitter.com/9suZeDyY8Q
M Street (Washington, D.C.) pic.twitter.com/ztjKiTr9ZM
— AI-generated street transformations (@betterstreetsai) July 29, 2022
Prompt: "A nuclear power plant in utopia by Simon Stålenhag and Grant Wood, oil on canvas" (#StableDiffusion) pic.twitter.com/NMekFJjMc9
— Rivers Have Wings (@RiversHaveWings) August 8, 2022
In media, anyone with creativity will be able to bring their visions to life - no production team, illustrators, or actors required. I absolutely love this prototype tool, which helps you draw in a collaborative way with Stable Diffusion. Imagine how advanced the tools will be in a few months!
W.I.P. collage tool for stable diffusion pic.twitter.com/CYWMBhsHn4
— Gene Kogan (@genekogan) August 4, 2022
Over in my industry, the tedium of writing code will be replaced by code assistants which translate architectural and conceptual designs into working applications. Large language models like GPT-3 Codex/GitHub Copilot will generate the code, but I believe that image and video models will help answer questions, visualize data, diagram systems, and present customized interfaces with minimal human feedback.
i've been saying this since copilot was released. my stackoverflow searches dropped by at least -50%, easy
— gian (@giansegato) August 19, 2022
there's no way people could code without google. now, there's no way i could code (as efficiently) without AI assisting me https://t.co/I0jti3BVKQ
Education is an extremely underexplored area for innovation in this arena. I believe that we'll be able to generate learning plans customized to the individual, with audio, video, and text curricula generated for whatever style and repetition pattern is best.
I can't wait to see what's in store for manufacturing. We'll be able to generate realistic renders and 3D models, and deliver exactly what a client requests for rapid prototyping.
AI image generators are just a few lines of code away from being able to render 360° images https://t.co/HpQ1uGeQr0
— Matt Boegner (@MattBoegner) August 5, 2022
Multi-Domain Applications
It's not just images. Stable Diffusion is a text-to-image model, but most of the underlying technical innovations translate to other mediums as well. The past few months have been a whirlwind of accelerating progress, and I struggle to articulate just how quickly the field is advancing!
Where are we now, on August 21st, 2022?
Video generated from text is occurring on a research scale and will begin to propagate freely later this year. One of the collaborating organizations on the Stable Diffusion model released this example of text-to-video editing:
#stablediffusion text-to-image checkpoints are now available for research purposes upon request at https://t.co/7SFUVKoUdl
— Patrick Esser (@pess_r) August 11, 2022
Working on a more permissive release & inpainting checkpoints.
Soon™ coming to @runwayml for text-to-video-editing pic.twitter.com/7XVKydxTeD
My best estimate is that high-quality video models will be available to the public at some time in mid-2023. This is incredible. An eight-year-old child could be the creator of the next Frozen, and an octagenarian could remake the classic films of their youth. Full-length AI-generated movies are only a few years away, depending on how you want to quantify the quality and human level of involvement in generating a film.
As for audio, you may not know that voice transformations are already at a professional level (see here, for example). Text-to-speech applications have drastically improved in the past couple of years (including translation services!), although they still have some room for improvements. But one of the most transformative applications may be in music, where several teams are working on improving models for music generation in the style of OpenAI's Jukebox. One of those teams is Harmonai, which is in the Stability AI ecosystem.
At this point, I want to step back to reference the incredible improvements in large language model capabilities like OpenAI's GPT-3 or EleutherAI's GPT-J. These models, often called Foundation Models, are trained on a massive corpus of data and adapted to many applications.
For example, Google's state-of-the-art PaLM (Pathways Language Model) is a text model which demonstrates breakthroughs in multiple categories. It has 540 billion parameters and accurately completes a variety of language, reasoning, and code tasks without having to be specifically trained to do those tasks. It can accurately explain complex jokes, write working code in multiple languages, and decompose reasoning. The open-source equivalents are at most a few months behind.

There is a co-evolution present with the capabilities of models like Stable Diffusion, wherein more capable text models allow for image, video, or audio models which more accurately depict the intent of users. We can collaboratively work with an AI-powered program to create or edit content in ways that were previously impossible.
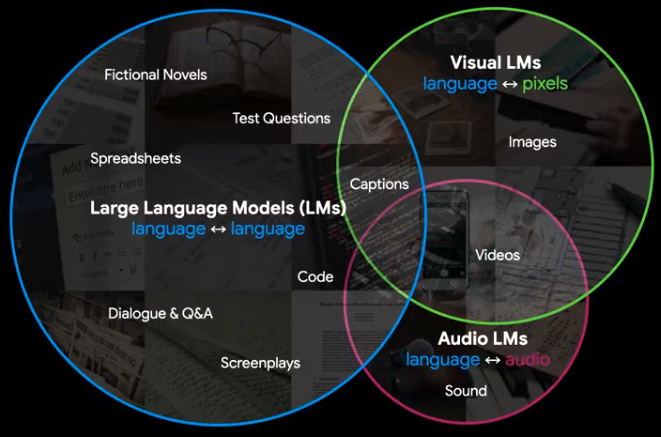
Putting the pieces together, the following hypothetical use case can be conducted in 2022:
- Provide voice directions to a robot
- Robot uses a video camera to determine its location in an unfamiliar setting
- Robot explains its routing decisions via conversational text
- And generates a 3D rendering of its environment
Alternate AI Deployment Patterns
Stable Diffusion is being released in a permissive, widely available manner which is primed for customization and fine-tuning.
Release Scope
The open-source AI art scene was catalyzed by OpenAI's release of CLIP in January 2021, from which several open source models were developed. Crucially, the early leaders in the AI art space like OpenAI (DALLE-2) and Google (Imagen) have avoided releases of their text-to-image model weights in an open source fashion. They reasoned that there are too many known model biases (not to mention PR considerations and political pressures) to safely release the full engine and weights. OpenAI's commercial offering of DALLE-2 is limited in terms of licensed usages and does not show signs of changing course.
The folks behind Stable Diffusion don't agree with the risk-averse approach of other players, while firmly believing in the open source model and making no claims to images produced by it. They encourage derivations and customizations, including applications built on top of the model. For better or for worse, this model's release prominently bucks the restrictions used by the major research organizations in AI.
Note: the core image dataset was trained on LAION-Aesthetics, a soon to be released subset of LAION 5B. The model weights will be released on Hugging Face.
Model Weights & Performance
Stable Diffusion is trained on about 2 billion representative images and descriptions from the internet. The development team has been able to compress the model down to about 2 Gb and it runs on as little as 5.1Gb VRAM. In other words, the model should be able to run on Macs with M2 chips as well as a variety of gaming-capable PC's/consumer GPU's.
This is groundbreaking! The miniscule size and efficient performance of the model removes many current limitations to working with AI image models. From a cost and development standpoint, anyone with an internet connection and decent PC will have the means to integrate Stable Diffusion or derivative models into custom applications!
From a customer adoption standpoint, I fully expect that many handheld devices will be able to run streamlined derivative models (i.e. edge computing architecture) backed by more powerful models running in the cloud.
Fine-Tuning & Customization
In the near future, Stable Diffusion plans to support the textual_inversion fine-tuning library:
Using only 3-5 images of a user-provided concept, like an object or a style, we learn to represent it through new "words" in the embedding space of a frozen text-to-image model. These "words" can be composed into natural language sentences, guiding personalized creation in an intuitive way. Notably, we find evidence that a single word embedding is sufficient for capturing unique and varied concepts.
Translation: holy crap! With a bit of sophistication, every user of an image generation app could run their own custom model, tuned to their liking. The users won't have to know anything about the techniques behind model knowledge transfer, as the applications will hide those details. All that the user would see are requests for basic image descriptions and standard UI/UX like upvotes or ratings to assess the best images.
Conclusion
I believe that the public release of Stable Diffusion will set in motion a new pattern for how AI-powered applications are created and deployed. We are about to witness a new era in creativity, and I hope that we collectively use those capabilities to build a brighter future.
Appendix
Quantifiable Predictions:
- The valuation of generative media companies will exceed Netflix market cap by the end of 2024.
- Generative models will be mentioned in an official televised debate between the candidates for the 2024 Presidential Election (inclusive of the late-round DNC/RNC debates)
- Media generated by a latent diffusion model will appear in a SuperBowl commercial by SuperBowl LVIII (February 2024)
- The front page of Reddit will have AI-generated media present in at least 20% of media posts on January 2nd, 2024. I will also count text posts generated in a significant way by large language models.
- New engines for music and videos generated from text will make an appearance by the end of 2022, with high-quality models available to the public in mid-2023.
- A Billboard Top 10 song will have its musical accompaniment synthesized by AI by the end of 2024.
Author's Note: The cover images are generated by Stable Diffusion using prompts written by me. This post was written with some grammatical refinements courtesy of GPT-3. Some parts of the post were first transcribed using Google's speech-to-text API.